AWS Transcribe
AWS Transcribe is an automatic speech recognition (ASR) service that makes it easy to add speech-to-text capabilities to your applications. It converts audio and video files into accurate text transcriptions, enabling easier content indexing, search, and analysis.
Key Features
- Speech-to-Text Conversion: Converts audio and video files into accurate text transcriptions.
- Automatic Punctuation: Adds punctuation and formatting to transcriptions for better readability.
- Speaker Identification: Identifies and labels different speakers in a conversation or recording.
- Custom Vocabulary: Allows the addition of custom vocabulary and terms to improve transcription accuracy for specific jargon or names.
- Real-Time Transcription: Provides streaming transcription for real-time applications and live broadcasts.
- Multi-Language Support: Supports multiple languages and dialects for transcription.
Architecture Overview
The following diagram illustrates how AWS Transcribe processes audio and video files for transcription:
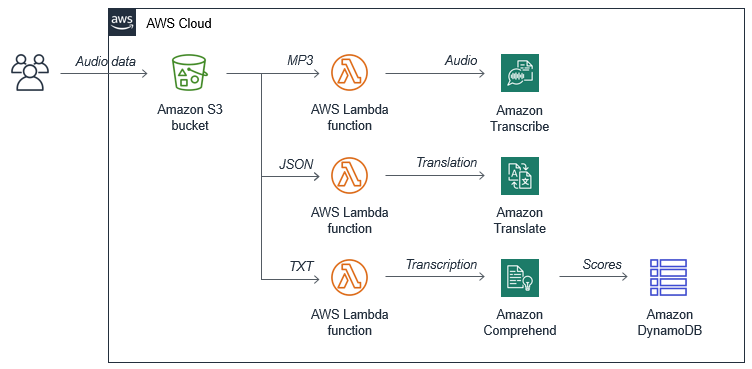
- Audio/Video Input: Upload audio or video files to Amazon S3 or stream directly to AWS Transcribe.
- Transcription Processing: AWS Transcribe processes the audio or video, converting speech into text.
- Text Output: Transcription results are available for download or retrieval through API.
- Integration: Results can be integrated into applications, search engines, or other AWS services.
Use Cases
- Content Indexing: Automatically transcribe and index audio and video content for easier search and retrieval.
- Accessibility: Provide transcripts for videos to improve accessibility for hearing-impaired users.
- Customer Service: Transcribe customer service calls for analysis and improving customer support.
- Media and Entertainment: Create transcripts for interviews, podcasts, and media content for better content management.
Integration with Other AWS Services
AWS Transcribe integrates with several AWS services to enhance its capabilities:
- Amazon S3: Store audio and video files for processing and manage transcription results.
- AWS Lambda: Automate workflows and integrate transcription results into applications using Lambda functions.
- Amazon Comprehend: Analyze transcriptions for sentiment, key phrases, and other insights using Comprehend.
- Amazon Kinesis: Stream real-time audio data to Transcribe for live transcription and analysis.
Things to Remember for the Exam
- AWS Transcribe provides automatic speech-to-text conversion for audio and video files.
- Key features include speech-to-text conversion, automatic punctuation, speaker identification, and custom vocabulary support.
- Understand how AWS Transcribe processes audio/video input, generates transcription results, and integrates with other AWS services.
- Be familiar with use cases such as content indexing, accessibility, customer service, and media management.
- Know how Transcribe integrates with services like S3, Lambda, Comprehend, and Kinesis for enhanced functionality.